How to Read Text from Image (OCR) in C# with IronOCR Tesseract
Photo by Danial Igdery
Originally Posted On: C# OCR – Image to Text – C# Tesseract | Iron OCR (ironsoftware.com)
Reading Text from Images in .Net Applications
In this tutorial, we will learn how to convert images to text in C# and other .NET languages.
We will use the IronOcr.IronTesseract class to recognize text within images and look at the nuances of how to use Iron Tesseract OCR to get the highest performance in terms of accuracy and speed when reading text from images in .NET
To achieve “Image to Text” we will install the IronOCR library into a Visual Studio project.
To do this, we download the IronOcr DLL or use Nuget .
PM > Install-Package IronOcr
Why IronOcr
We use IronOcr for Tesseract management because its us unique in that it:
- Works straight out of the box in pure .Net
- Doesn’t require Tesseract to be installed on your machine.
- Runs the latest engines: Tesseract 5 ( as well as Tesseract 4 & 3)
- Is available for any .Net project: .Net Framework 4.5 +, .Net Standard 2 + and .Net Core 2, 3 & 5!
- Has improved accuracy over and speed over traditional Tesseract
- Supports Xamarin, Mono, Azure and Docker
- Manage the complex Tesseract dictionary system using Nuget packages
- Supports PDFS, MultiFrame Tiffs and all major image formats without configuration
- Can correct low quality and skewed scans to get the best results from tesseract.
Using Tesseract in C#
In this simple example, you can see we use the IronOcr.IronTesseract class to read the text from an image and automatically return its value as a string.
- // PM> Install-Package IronOcr
- using IronOcr;
- var Result = new IronTesseract().Read(@”imgScreenshot.png”);
- Console.WriteLine(Result.Text);
Copy code to clipboardVB C#
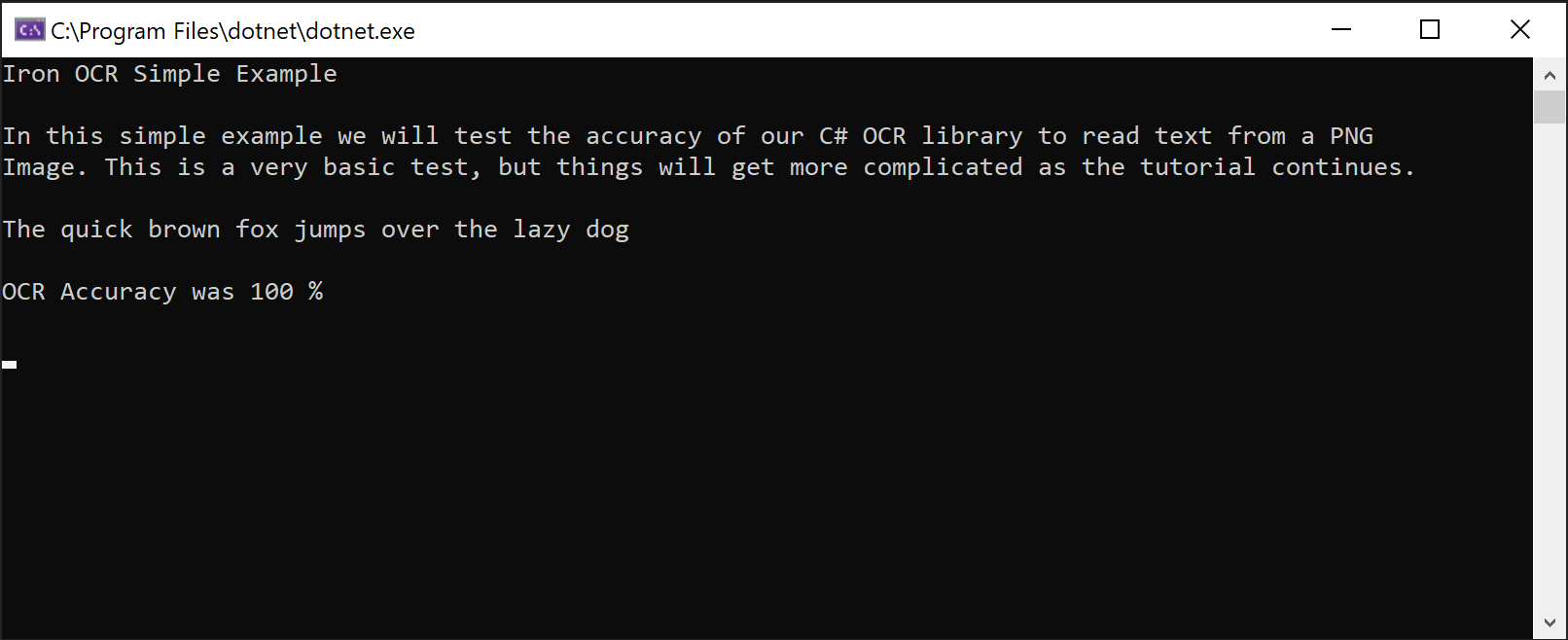
Which results in 100% accuracy with the following text:
Iron OCR Simple Example In this simple example we will test the accuracy of our C# OCR library to read text from a PNG Image. This is a very basic test, but things will get more complicated as the tutorial continues. The quick brown fox jumps over the lazy dog
Although this may seem simplistic, there is sophisticated behavior going on ‘under the surface’: scanning the image for alignment, quality and resolution, looking at its properties, optimizing the OCR engine, and using a trained artificial intelligence network to then read the text as a human would.
OCR is not a simple process for a computer to achieve, and reading speeds may be similar to those of a human. In other words, OCR is not an instantaneous process. In this case though, it is 100% accurate.
Advanced Use of Iron OCR Tesseract for C#
In most real world use cases, developers are going to want the best performance possible for their project. In this case, we recommend that you move forward to use the OcrInput and IronTesseract classes within the IronOcr namespace.
OcrInput gives you the facility to set the specific characteristics of an OCR job, such as:
- Working with almost any type of image including JPEG, TIFF, GIF, BMP & PNG
- Importing whole or parts of PDF documents
- Enhancing contrast, resolution & size
- Correcting for rotation, scan noise, digital noise, skew, negative images
IronTesseract
- Pick from hundreds of prepackaged language and language variants
- Use Tesseract 5, 4 or 3 OCR engines “out-of-the-box”
- Specify a document type whether we are looking at a screenshot, a snippet, or an entire document
- Read Barcodes
- Output results to: Searchable PDFs, Hocr HTML , a DOM & Strings
Example: Getting Started with OcrInput + IronTesseract
This all may seem daunting, but in the example below you will see the default settings which we would recommend you start with, which will work with almost any image you input to Iron OCR.
- using IronOcr;
- var Ocr = new IronTesseract();
- using (var Input = new OcrInput(@”imgPotter.tiff”)) {
- var Result = Ocr.Read(Input);
- Console.WriteLine(Result.Text);
- }
Copy code to clipboardVB C#
We can use this even on a medium quality scan with 100% accuracy.

As you can see, reading the text (and optionally barcodes) from a scanned image such as a TIFF was rather easy. This OCR job yields an accuracy of 100%.
OCR is not a perfect science when it comes to real world documents, yet IronTesseract is about as good as it gets.
You will also note that Iron OCR can automatically read multi-page documents, such as TIFFs and even extract text from PDF documents automatically.
Example: A Low Quality Scan

Now we will try a much lower quality scan of the same page, at a low DPI, which has lots of distortion and digital noise and damage to the original paper.
This is where IronOCR truly shines against other OCR libraries such as Tesseract, and we will find alternative OCR projects shy away from discussing. OCR on real world scanned images rather than unrealistically ‘perfect’ test cases created digitally to give a 100% OCR accuracy.
- using IronOcr;
- var Ocr = new IronTesseract();
- using (var Input = new OcrInput(@”imgPotter.LowQuality.tiff”))
- {
- Input.Deskew(); // removes rotation and perspective
- var Result = Ocr.Read(Input);
- Console.WriteLine(Result.Text);
- }
Copy code to clipboardVB C#
Without adding Input.Deskew() to straighten the image we get a 52.5% accuracy. Not good enough.
Adding Input.Deskew() brings us to 99.8% accuracy which is almost as accurate as the OCR of a high quality scan.
Image Filters may take a little time to run – but also reduce OCR processing time. It is a fine balance for a developer to get. to know their input documents.
If you are not certain:
- Input.Deskew() is a safe and very successful filter to use.
- Secondly try Input.DeNoise() to fix considerable digital noise.
Performance Tuning
The most important factor in the speed of an OCR job is in fact the quality of the input image. The less background noise that is present and the higher the dpi, with a perfect target dpi at about 200 dpi, will cause the fastest and most accurate OCR results.
This is not, however, necessary, as Iron OCR shines at correcting imperfect documents (though this is time-consuming and will cause your OCR jobs to use more CPU cycles).
If possible, choosing input image formats with less digital noise such as TIFF or PNG can also yield faster results than lossy image formats such as JPEG.
Image Filters
The following Image filters can really improve performance:
- OcrInput.Rotate( double degrees) – Rotates images by a number of degrees clockwise. For anti-clockwise, use negative numbers.
- OcrInput.Binarize() – This image filter turns every pixel black or white with no middle ground. May Improve OCR performance cases of very low contrast of text to background.
- OcrInput.ToGrayScale() – This image filter turns every pixel into a shade of grayscale. Unlikely to improve OCR accuracy but may improve speed
- OcrInput.Contrast() – Increases contrast automatically. This filter often improves OCR speed and accuracy in low contrast scans.
- OcrInput.DeNoise() – Removes digital noise. This filter should only be used where noise is expected.
- OcrInput.Invert() – Inverts every color. E.g. White becomes black : black becomes white.
- OcrInput.Dilate() – Advanced Morphology. Dilation adds pixels to the boundaries of objects in an image. Opposite of Erode
- OcrInput.Erode() – Advanced Morphology. Erosion removes pixels on object boundariesOpposite of Dilate
- OcrInput.Deskew() – Rotates an image so it is the right way up and orthogonal. This is very useful for OCR because Tesseract tolerance for skewed scans can be as low as 5 degrees.
- OcrInput.DeepCleanBackgroundNoise() – Heavy background noise removal. Only use this filter in case extreme document background noise is known, because this filter will also risk reducing OCR accuracy of clean documents, and is very CPU expensive.
- OcrInput.EnhanceResolution – Enhances the resolution of low quality images. This filter is not often needed because OcrInput.MinimumDPI and OcrInput.TargetDPI will automatically catch and resolve low resolution inputs.
Performance Tuning for Speed
Using Iron Tesseract, we may wish to speed up OCR on higher quality scans.
If optimizing for speed we might start at this position and then turn features back on until the perfect balance is found.
- using IronOcr;
- var Ocr = new IronTesseract();
- // Configure for speed
- Ocr.Configuration.BlackListCharacters = “~`$#^*_}{][|@”;
- Ocr.Configuration.PageSegmentationMode = TesseractPageSegmentationMode.Auto;
- Ocr.Configuration.TesseractVersion = TesseractVersion.Tesseract5;
- Ocr.Configuration.EngineMode = TesseractEngineMode.LstmOnly;
- Ocr.Language = OcrLanguage.EnglishFast;
- using (var Input = new OcrInput(@”imgPotter.tiff”))
- {
- var Result = Ocr.Read(Input);
- Console.WriteLine(Result.Text);
- }
Copy code to clipboardVB C#
This result is 99.8% accurate compared to baseline 100% – but 35% faster.
Reading Cropped Regions of Images
As you can see from the following code sample, Iron’s fork of Tesseract OCR is adept at reading specific areas of images.
We may use a System.Drawing.Rectangle to specify, in pixels, the exact area of an image to read.
This can be incredibly useful when we are dealing with a standardized form which is filled out, where only a certain area has text which changes from case to case.
Example: Scanning an Area of a Page
We can use a System.Drawing.Rectangle to specify a region in which we will read a document. The unit of measurement is always pixels.
We will see that this provides speed improvements as well as avoiding reading unnecessary text. In this example we will read a student’s name from a central area of a standardized document.


- using IronOcr;
- var Ocr = new IronTesseract();
- using (var Input = new OcrInput())
- {
- // a 41% improvement on speed
- var ContentArea = new System.Drawing.Rectangle() { X = 215, Y = 1250, Height = 280, Width = 1335 };
- Input.AddImage(“img/ComSci.png”, ContentArea);
- var Result = Ocr.Read(Input);
- Console.WriteLine(Result.Text);
- }
Copy code to clipboardVB C#
This yields a 41% speed increase – and allows us to be specific. This is incredibly useful for .Net OCR scenarios where documents are similar and consistent such as Invoices, Receipts, Checks, Forms, Expense Claims etc.
ContentAreas (OCR cropping) is also supported when reading PDFs.
International Languages
Iron OCR supports 125 international languages via language packs which are distributed as DLLs, which can be downloaded from this website, or also from the NuGet Package Manager for Visual Studio.
We can install them by browsing NuGet (search for “IronOcr.Languages”) or from the OCR language packs page.
Supported languages Include:
- Afrikaans
- Amharic Also known as አማርኛ
- Arabic Also known as العربية
- ArabicAlphabet Also known as العربية
- ArmenianAlphabet Also known as Հայերեն
- Assamese Also known as অসমীয়া
- Azerbaijani Also known as azərbaycan dili
- AzerbaijaniCyrillic Also known as azərbaycan dili
- Belarusian Also known as беларуская мова
- Bengali Also known as Bangla,বাংলা
- BengaliAlphabet Also known as Bangla,বাংলা
- Tibetan Also known as Tibetan Standard, Tibetan, Central ཡིག་
- Bosnian Also known as bosanski jezik
- Breton Also known as brezhoneg
- Bulgarian Also known as български език
- CanadianAboriginalAlphabet Also known as Canadian First Nations, Indigenous Canadians, Native Canadian, Inuit
- Catalan Also known as català, valencià
- Cebuano Also known as Bisaya, Binisaya
- Czech Also known as čeština, český jazyk
- CherokeeAlphabet Also known as ᏣᎳᎩ ᎦᏬᏂᎯᏍᏗ, Tsalagi Gawonihisdi
- ChineseSimplified Also known as 中文 (Zhōngwén), 汉语, 漢語
- ChineseSimplifiedVertical Also known as 中文 (Zhōngwén), 汉语, 漢語
- ChineseTraditional Also known as 中文 (Zhōngwén), 汉语, 漢語
- ChineseTraditionalVertical Also known as 中文 (Zhōngwén), 汉语, 漢語
- Cherokee Also known as ᏣᎳᎩ ᎦᏬᏂᎯᏍᏗ, Tsalagi Gawonihisdi
- Corsican Also known as corsu, lingua corsa
- Welsh Also known as Cymraeg
- CyrillicAlphabet Also known as Cyrillic scripts
- Danish Also known as dansk
- DanishFraktur Also known as dansk
- German Also known as Deutsch
- GermanFraktur Also known as Deutsch
- DevanagariAlphabet Also known as Nagair,देवनागरी
- Divehi Also known as ދިވެހި
- Dzongkha Also known as རྫོང་ཁ
- Greek Also known as ελληνικά
- English
- MiddleEnglish Also known as English (1100-1500 AD)
- Esperanto
- Estonian Also known as eesti, eesti keel
- EthiopicAlphabet Also known as Ge’ez,ግዕዝ, Gəʿəz
- Basque Also known as euskara, euskera
- Faroese Also known as føroyskt
- Persian Also known as فارسی
- Filipino Also known as National Language of the Philippines, Standardized Tagalog
- Finnish Also known as suomi, suomen kieli
- Financial Also known as Financial, Numerical and Technical Documents
- French Also known as français, langue française
- FrakturAlphabet Also known as Generic Fraktur, Calligraphic hand of the Latin alphabet
- Frankish Also known as Frenkisk, Old Franconian
- MiddleFrench Also known as Moyen Français,Middle French (ca. 1400-1600 AD)
- WesternFrisian Also known as Frysk
- GeorgianAlphabet Also known as ქართული
- ScottishGaelic Also known as Gàidhlig
- Irish Also known as Gaeilge
- Galician Also known as galego
- AncientGreek Also known as Ἑλληνική
- GreekAlphabet Also known as ελληνικά
- Gujarati Also known as ગુજરાતી
- GujaratiAlphabet Also known as ગુજરાતી
- GurmukhiAlphabet Also known as Gurmukhī, ਗੁਰਮੁਖੀ, Shahmukhi, گُرمُکھی, Sihk Script
- HangulAlphabet Also known as Korean Alphabet,한글,Hangeul,조선글,hosŏn’gŭl
- HangulVerticalAlphabet Also known as Korean Alphabet,한글,Hangeul,조선글,hosŏn’gŭl
- HanSimplifiedAlphabet Also known as Samhan ,한어, 韓語
- HanSimplifiedVerticalAlphabet Also known as Samhan ,한어, 韓語
- HanTraditionalAlphabet Also known as Samhan ,한어, 韓語
- HanTraditionalVerticalAlphabet Also known as Samhan ,한어, 韓語
- Haitian Also known as Kreyòl ayisyen
- Hebrew Also known as עברית
- HebrewAlphabet Also known as עברית
- Hindi Also known as हिन्दी, हिंदी
- Croatian Also known as hrvatski jezik
- Hungarian Also known as magyar
- Armenian Also known as Հայերեն
- Inuktitut Also known as ᐃᓄᒃᑎᑐᑦ
- Indonesian Also known as Bahasa Indonesia
- Icelandic Also known as Íslenska
- Italian Also known as italiano
- ItalianOld Also known as italiano
- JapaneseAlphabet Also known as 日本語 (にほんご)
- JapaneseVerticalAlphabet Also known as 日本語 (にほんご)
- Javanese Also known as basa Jawa
- Japanese Also known as 日本語 (にほんご)
- JapaneseVertical Also known as 日本語 (にほんご)
- Kannada Also known as ಕನ್ನಡ
- KannadaAlphabet Also known as ಕನ್ನಡ
- Georgian Also known as ქართული
- GeorgianOld Also known as ქართული
- Kazakh Also known as қазақ тілі
- Khmer Also known as ខ្មែរ, ខេមរភាសា, ភាសាខ្មែរ
- KhmerAlphabet Also known as ខ្មែរ, ខេមរភាសា, ភាសាខ្មែរ
- Kyrgyz Also known as Кыргызча, Кыргыз тили
- NorthernKurdish Also known as Kurmanji, کورمانجی ,Kurmancî
- Korean Also known as 한국어 (韓國語), 조선어 (朝鮮語)
- KoreanVertical Also known as 한국어 (韓國語), 조선어 (朝鮮語)
- Lao Also known as ພາສາລາວ
- LaoAlphabet Also known as ພາສາລາວ
- Latin Also known as latine, lingua latina
- LatinAlphabet Also known as latine, lingua latina
- Latvian Also known as latviešu valoda
- Lithuanian Also known as lietuvių kalba
- Luxembourgish Also known as Lëtzebuergesch
- Malayalam Also known as മലയാളം
- MalayalamAlphabet Also known as മലയാളം
- Marathi Also known as मराठी
- MICR Also known as Magnetic Ink Character Recognition, MICR Cheque Encoding
- Macedonian Also known as македонски јазик
- Maltese Also known as Malti
- Mongolian Also known as монгол
- Maori Also known as te reo Māori
- Malay Also known as bahasa Melayu, بهاس ملايو
- Myanmar Also known as Burmese ,ဗမာစာ
- MyanmarAlphabet Also known as Burmese ,ဗမာစာ
- Nepali Also known as नेपाली
- Dutch Also known as Nederlands, Vlaams
- Norwegian Also known as Norsk
- Occitan Also known as occitan, lenga d’òc
- Oriya Also known as ଓଡ଼ିଆ
- OriyaAlphabet Also known as ଓଡ଼ିଆ
- Panjabi Also known as ਪੰਜਾਬੀ, پنجابی
- Polish Also known as język polski, polszczyzna
- Portuguese Also known as português
- Pashto Also known as پښتو
- Quechua Also known as Runa Simi, Kichwa
- Romanian Also known as limba română
- Russian Also known as русский язык
- Sanskrit Also known as संस्कृतम्
- Sinhala Also known as සිංහල
- SinhalaAlphabet Also known as සිංහල
- Slovak Also known as slovenčina, slovenský jazyk
- SlovakFraktur Also known as slovenčina, slovenský jazyk
- Slovene Also known as slovenski jezik, slovenščina
- Sindhi Also known as सिन्धी, سنڌي، سندھی
- Spanish Also known as español, castellano
- SpanishOld Also known as español, castellano
- Albanian Also known as gjuha shqipe
- Serbian Also known as српски језик
- SerbianLatin Also known as српски језик
- Sundanese Also known as Basa Sunda
- Swahili Also known as Kiswahili
- Swedish Also known as Svenska
- Syriac Also known as Syrian, Syriac Aramaic,ܠܫܢܐ ܣܘܪܝܝܐ, Leššānā Suryāyā
- SyriacAlphabet Also known as Syrian, Syriac Aramaic,ܠܫܢܐ ܣܘܪܝܝܐ, Leššānā Suryāyā
- Tamil Also known as தமிழ்
- TamilAlphabet Also known as தமிழ்
- Tatar Also known as татар теле, tatar tele
- Telugu Also known as తెలుగు
- TeluguAlphabet Also known as తెలుగు
- Tajik Also known as тоҷикӣ, toğikī, تاجیکی
- Tagalog Also known as Wikang Tagalog, ᜏᜒᜃᜅ᜔ ᜆᜄᜎᜓᜄ᜔
- Thai Also known as ไทย
- ThaanaAlphabet Also known as Taana , Tāna , ތާނަ
- ThaiAlphabet Also known as ไทย
- TibetanAlphabet Also known as Tibetan Standard, Tibetan, Central ཡིག་
- Tigrinya Also known as ትግርኛ
- Tonga Also known as faka Tonga
- Turkish Also known as Türkçe
- Uyghur Also known as Uyƣurqə, ئۇيغۇرچە
- Ukrainian Also known as українська мова
- Urdu Also known as اردو
- Uzbek Also known as O‘zbek, Ўзбек, أۇزبېك
- UzbekCyrillic Also known as O‘zbek, Ўзбек, أۇزبېك
- Vietnamese Also known as Tiếng Việt
- VietnameseAlphabet Also known as Tiếng Việt
- Yiddish Also known as ייִדיש
- Yoruba Also known as Yorùbá
Example: OCR in Arabic (+ many more)
In the following example, we will show how we can scan an Arabic document.
PM> Install-Package IronOcr.Languages.Arabic
- // using IronOcr;
- // PM> Install IronOcr.Languages.Arabic
- var Ocr = new IronTesseract();
- Ocr.Language = OcrLanguage.Arabic;
- using (var input = new OcrInput())
- {
- input.AddImage(“img/arabic.gif”);
- // add image filters if needed
- // In this case, even thought input is very low quality
- // IronTesseract can read what conventional Tesseract cannot.
- var Result = Ocr.Read(input);
- // Console can’t print Arabic on Windows easily.
- // Let’s save to disk instead.
- Result.SaveAsTextFile(“arabic.txt”);
- }
Copy code to clipboardVB C#
Example: OCR in more than one language in the same document.
In the following example, we will show how to OCR scan multiple languages to the same document.
This is actually very common, where for example a Chinese document might contain English words and Urls.
PM> Install-Package IronOcr.Languages.ChineseSimplified
- using IronOcr;
- var Ocr = new IronTesseract();
- Ocr.Language = OcrLanguage.ChineseSimplified;
- Ocr.AddSecondaryLanguage(OcrLanguage.English);
- // We can add any number of languages.
- // Optionally add custom tesseract .traineddata files by specifying a file path
- using (var input = new OcrInput())
- {
- input.AddImage(“img/MultiLanguage.jpeg”);
- var Result = Ocr.Read(input);
- Result.SaveAsTextFile(“MultiLanguage.txt”);
- }
Copy code to clipboardVB C#
Multi Page Documents
IronOcr can combine multiple pages / images into a single OcrResult. This is extremely useful where a document has been made from multiple images. We will see later that this special feature of IronTesseract is extremely useful to produce searchable PDFs and HTML files from OCR inputs.
IronOcr makes it possible to “mix and match” images, TIFF frames and PDF pages into a single OCR input.
- using IronOcr;
- var Ocr = new IronTesseract();
- using (var input = new OcrInput())
- {
- input.AddImage(“image1.jpeg”);
- input.AddImage(“image2.png”);
- input.AddImage(“image3.gif”);
- var Result = Ocr.Read(input);
- Console.WriteLine($”{Result.Pages.Count()} Pages”);
- // 3 Pages
- }
Copy code to clipboardVB C#
We can also easily OCR every page of a TIFF.
- using IronOcr;
- var Ocr = new IronTesseract();
- using (var input = new OcrInput())
- {
- input.AddMultiFrameTiff(“MultiFrame.Tiff”);
- var Result = Ocr.Read(input);
- Console.WriteLine(Result.Text);
- Console.WriteLine($”{Result.Pages.Count()} Pages”);
- // 1 page for every frame (page) in the TIFF
- }
Copy code to clipboardVB C#
- var Ocr = new IronTesseract();
- using (var input = new OcrInput())
- {
- input.AddPdf(“example.pdf”,”password”);
- // We can also select specific PDF page numbers to OCR
- var Result = Ocr.Read(input);
- Console.WriteLine(Result.Text);
- Console.WriteLine($”{Result.Pages.Count()} Pages”);
- // 1 page for every page of the PDF
- }
Copy code to clipboardVB C#
Searchable PDFs
Exporting OCR results as searchable PDFs in C# and VB.Net is a popular feature of IronOCR. This can really help with database population, SEO and PDF usability businesses and governments.
- using IronOcr;
- var Ocr = new IronTesseract();
- using (var input = new OcrInput())
- {
- input.Title = “Quarterly Report”
- input.AddImage(“image1.jpeg”);
- input.AddImage(“image2.png”);
- input.AddImage(“image3.gif”);
- var Result = Ocr.Read(input);
- Result.SaveAsSearchablePdf(“searchable.pdf”)
- }
Copy code to clipboardVB C#
Another OCR trick is to convert an existing PDF document searchable.
- using IronOcr;
- var Ocr = new IronTesseract();
- using (var input = new OcrInput())
- {
- input.Title = “Pdf Metadata Name”
- input.AddPdf(“example.pdf”,”password”);
- var Result = Ocr.Read(input);
- Result.SaveAsSearchablePdf(“searchable.pdf”)
- }
Copy code to clipboardVB C#
The same applies to converting TIFF documents with 1 or more pages to searchable PDFs using IronTesseract.
- using IronOcr;
- var Ocr = new IronTesseract();
- using (var input = new OcrInput())
- {
- input.Title = “Pdf Title”
- input.AddMultiFrameTiff(“example.tiff”)
- var Result = Ocr.Read(input);
- Result.SaveAsSearchablePdf(“searchable.pdf”)
- }
Copy code to clipboardVB C#
Exporting Hocr HTML
We can similarly export OCR result documents to Hocr HTML. This is an XML document which can be parsed by an XML reader, or marked up into visually appealing HTML.
This allows some degree of PDF to HTML and TIFF to HTML conversion.
- using IronOcr;
- var Ocr = new IronTesseract();
- using (var Input = new OcrInput()) {
- input.Title = “Html Title”
- // Add more content as required…
- //input.AddImage(“image2.jpeg”);
- //input.AddPdf(“example.pdf”,”password”);
- //input.AddMultiFrameTiff(“example.tiff”)
- var Result = Ocr.Read(Input);
- Result.SaveAsHocrFile(“hocr.html”);
- }
Copy code to clipboardVB C#
Reading Barcodes in OCR Documents
IronOCR has a unique additional advantage over traditional tesseract in that it also reads barcodes and QR codes;
- var Ocr = new IronTesseract();
- Ocr.Configuration.ReadBarCodes = true;
- using (var input = new OcrInput())
- {
- input.AddImage(“img/Barcode.png”);
- var Result = Ocr.Read(input);
- foreach (var Barcode in Result.Barcodes) {
- Console.WriteLine(Barcode.Value);
- // type and location properties also exposed
- }
- }
Copy code to clipboardVB C#
A Detailed Look at Image to Text OCR Results
The last thing we will look at in this tutorial is the OCR results object. When we read OCR, we normally only want the text out, but Iron OCR actually contains a huge amount of information which may be of use to advanced developers.
Within an OCR results object, we have a collection of pages which can be iterated. Within each page, we may find barcodes, power graphs, lines of text, words, and characters.
Each of these objects in fact contains: a location; an X coordinate; a Y coordinate; a width and a height; an image associated with it which can be inspected; a font name; the font size; the direction in which the text is written; the rotation of the text; and the statistical confidence that Iron OCR has for that specific word, line, or paragraph.
In short, this allows developers to be creative and work with OCR data in any way they choose to inspect and export information.
We can also work with and export any element from the .Net OCR Results object such as a paragraph, word or barcode as an Image or BitMap.
- using IronOcr;
- using System.Drawing; //for image export
- // We can delve deep into OCR results as an object model of
- // Pages, Barcodes, Paragraphs, Lines, Words and Characters
- // This allows us to explore, export and draw OCR content using other APIs/
- var Ocr = new IronTesseract();
- Ocr.Configuration.EngineMode = TesseractEngineMode.TesseractAndLstm;
- Ocr.Configuration.ReadBarCodes = true;
- using (var Input = new OcrInput(@”imgPotter.tiff”))
- {
- OcrResult Result = Ocr.Read(Input);
- foreach (var Page in Result.Pages)
- {
- // Page object
- int PageNumber = Page.PageNumber;
- string PageText = Page.Text;
- int PageWordCount = Page.WordCount;
- // null if we don’t set Ocr.Configuration.ReadBarCodes = true;
- OcrResult.Barcode[] Barcodes = Page.Barcodes;
- System.Drawing.Bitmap PageImage = Page.ToBitmap(Input);
- int PageWidth = Page.Width;
- int PageHeight = Page.Height;
- foreach (var Paragraph in Page.Paragraphs)
- {
- // Pages -> Paragraphs
- int ParagraphNumber = Paragraph.ParagraphNumber;
- String ParagraphText = Paragraph.Text;
- System.Drawing.Bitmap ParagraphImage = Paragraph.ToBitmap(Input);
- int ParagraphX_location = Paragraph.X;
- int ParagraphY_location = Paragraph.Y;
- int ParagraphWidth = Paragraph.Width;
- int ParagraphHeight = Paragraph.Height;
- double ParagraphOcrAccuracy = Paragraph.Confidence;
- OcrResult.TextFlow paragrapthText_direction = Paragraph.TextDirection;
- foreach (var Line in Paragraph.Lines)
- {
- // Pages -> Paragraphs -> Lines
- int LineNumber = Line.LineNumber;
- String LineText = Line.Text;
- System.Drawing.Bitmap LineImage = Line.ToBitmap(Input); ;
- int LineX_location = Line.X;
- int LineY_location = Line.Y;
- int LineWidth = Line.Width;
- int LineHeight = Line.Height;
- double LineOcrAccuracy = Line.Confidence;
- double LineSkew = Line.BaselineAngle;
- double LineOffset = Line.BaselineOffset;
- foreach (var Word in Line.Words)
- {
- // Pages -> Paragraphs -> Lines -> Words
- int WordNumber = Word.WordNumber;
- String WordText = Word.Text;
- System.Drawing.Image WordImage = Word.ToBitmap(Input);
- int WordX_location = Word.X;
- int WordY_location = Word.Y;
- int WordWidth = Word.Width;
- int WordHeight = Word.Height;
- double WordOcrAccuracy = Word.Confidence;
- if (Word.Font != null)
- {
- // Word.Font is only set when using Tesseract Engine Modes rather than LTSM
- String FontName = Word.Font.FontName;
- double FontSize = Word.Font.FontSize;
- bool IsBold = Word.Font.IsBold;
- bool IsFixedWidth = Word.Font.IsFixedWidth;
- bool IsItalic = Word.Font.IsItalic;
- bool IsSerif = Word.Font.IsSerif;
- bool IsUnderLined = Word.Font.IsUnderlined;
- bool IsFancy = Word.Font.IsCaligraphic;
- }
- foreach (var Character in Word.Characters)
- {
- // Pages -> Paragraphs -> Lines -> Words -> Characters
- int CharacterNumber = Character.CharacterNumber;
- String CharacterText = Character.Text;
- System.Drawing.Bitmap CharacterImage = Character.ToBitmap(Input);
- int CharacterX_location = Character.X;
- int CharacterY_location = Character.Y;
- int CharacterWidth = Character.Width;
- int CharacterHeight = Character.Height;
- double CharacterOcrAccuracy = Character.Confidence;
- // Output alternative symbols choices and their probability.
- // Very useful for spell checking
- OcrResult.Choice[] Choices = Character.Choices;
- }
- }
- }
- }
- }
- }
Copy code to clipboardVB C#
Summary
IronOCR provides C# developers the most advanced Tesseract API we know of on any platform.
IronOcr can be deployed on Windows, Linux, Mac, Azure , AWS, Lambda and supports .NET Framework projects as well as .Net Standard and .Net Core.
We can see that if we input even an imperfect document to IronOCR, it can accurately read its content to a statistical accuracy of about 99%, even though the document was badly formatted, skewed, and had digital noise.
We can also read barcodes in OCR scans, and even export our OCR as HTML and searchable PDFs.
This is unique to Iron OCR and is a feature you will not find in standard OCR libraries or vanilla Tesseract.
Moving Forward
To continue to learn more about Iron OCR, we recommend that you:
- Get Started with using our (C# Tesseract OCR Quickstart)[/csharp/ocr/docs/)] guide.
- Explore the C# & VB code examples
- Read the in-depth MSDN-style Object Reference.
Source Code Download
You may also enjoy the other .Net OCR tutorials in this section.